大數據服務 從數據采集到價值洞察的等距流程圖解
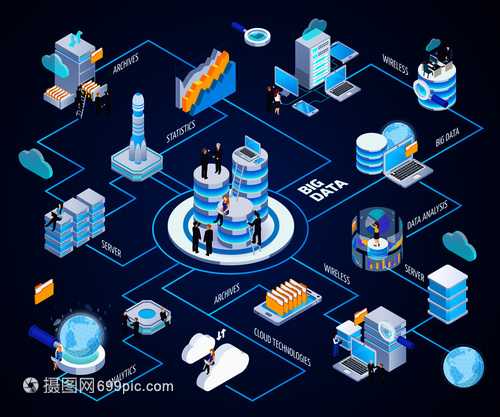
在大數據時代,數據已成為驅動企業決策、產品創新和業務增長的核心資產。大數據服務,正是將海量、多源、異構的原始數據,通過一系列系統化、標準化的流程,轉化為可行動的智能洞察與商業價值的過程。本文將通過一個結構清晰的等距流程圖解,為您拆解大數據服務的核心環節與流轉邏輯。
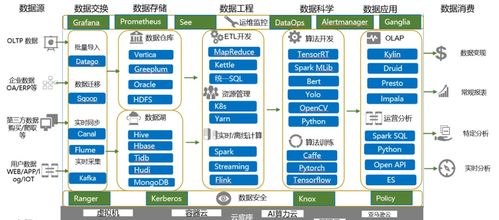
一、數據采集與匯聚層
流程的第一步是廣泛的數據采集。這如同為一座智慧工廠鋪設原料輸送管道。數據來源多種多樣,包括:
- 業務系統日志:來自網站、APP、CRM、ERP等內部系統,記錄用戶行為與交易數據。
- 物聯網設備數據:傳感器、智能硬件實時產生的時序數據。
- 外部公開數據:市場報告、社交媒體、公開API等。
- 第三方合作數據。
在這一層,服務的關鍵是建立穩定、高效、安全的數據接入通道,確保數據能夠實時或批量地、源源不斷地匯入數據池,為后續處理奠定基礎。
二、數據存儲與整合層
采集來的原始數據如同未經分類的礦石,需要被有序存放與初步整理。此環節涉及:
- 數據湖/數據倉庫:采用分布式文件系統(如HDFS)或云存儲構建海量數據存儲池,實現數據的低成本、高可靠保存。
- 數據清洗與標準化:剔除無效、錯誤、重復數據,并將不同格式的數據(結構化、半結構化、非結構化)進行格式統一與標準化。
- 元數據管理:建立數據的“戶口簿”,清晰記錄數據的來源、格式、含義與關系,便于查找與理解。
三、數據處理與計算層
這是大數據服務的“加工車間”,核心任務是將存儲層的數據進行深度加工。主要分為兩條并行的流水線:
- 批處理流水線:針對海量歷史數據進行離線、復雜的深度計算與分析。常用技術如MapReduce、Spark等,用于生成每日/每周報表、用戶畫像標簽、模型訓練數據集等。
- 流處理流水線:針對實時產生的數據流進行毫秒/秒級的即時處理與分析。常用技術如Flink、Storm、Kafka Streams等,用于實時監控、風險預警、實時推薦等場景。
四、數據分析與挖掘層
經過處理的數據已變為結構清晰、質量較高的“半成品”,本層則負責將其提煉成“高附加值產品”。
- 交互式分析:通過SQL或可視化BI工具(如Tableau, FineBI),讓業務人員能夠自主、靈活地進行數據查詢、報表制作與多維分析。
- 深度數據挖掘:運用機器學習、統計建模等算法,進行預測分析(如銷量預測)、聚類分析(如客戶分群)、關聯分析(如購物籃分析)等,發現數據背后隱藏的模式與規律。
五、數據服務與應用層
這是價值最終交付的環節,將分析洞察“封裝”成易于使用的服務,賦能前端業務。服務形式包括:
- API服務:將數據能力(如用戶畫像查詢、風險評分)以API接口形式提供給各業務系統調用。
- 數據產品:開發面向特定場景的獨立應用,如高管駕駛艙、精準營銷平臺、供應鏈優化系統等。
- 智能推薦/風控引擎:將模型直接嵌入業務流程,實現自動化、智能化的決策與干預。
六、數據治理與安全(貫穿全程的支撐體系)
此體系如同工廠的“質量管理與安全生產部門”,貫穿于以上所有環節,確保整個數據流程健康、合規、可信。它包括:
- 數據安全:通過加密、脫敏、訪問控制等手段,保障數據在傳輸、存儲、使用過程中的安全。
- 數據質量:建立質量監控規則,持續評估并提升數據的準確性、完整性、一致性。
- 數據合規:遵循GDPR等法律法規,對數據生命周期進行合規管理,特別是隱私數據的保護。
****
大數據服務的等距流程圖,清晰地展示了一條從“數據原料”到“智能產品”的現代化生產線。每一個環節都環環相扣,依賴強大的技術棧與科學的治理體系作為支撐。成功的大數據服務,不僅在于技術的先進,更在于能否以業務價值為導向,讓數據流順暢地穿越這六個層次,最終驅動企業實現數據驅動的精細化運營與智能決策。理解這一流程,是任何組織規劃和實施其大數據戰略的關鍵第一步。
如若轉載,請注明出處:http://www.65558a.cc/product/21.html
更新時間:2026-05-12 23:16:22